Contrastive Learning¶
Contrastive learning is a self-supervised learning method that learns feature representations to distinguish between similar and different samples.

Source: https://analyticsindiamag.com/contrastive-learning-self-supervised-ml/
Contrastive learning can be formulated as a score:
where \(x^+\) and \(x^-\) refers to a sample similar and different to \(x\), respectively.
What is SimCLR?¶
SimCLR is a contrastive learning framework introduced by Chen et. al that outperforms the previously SOTA supervised learning method on ImageNet when scaling up the architecture.
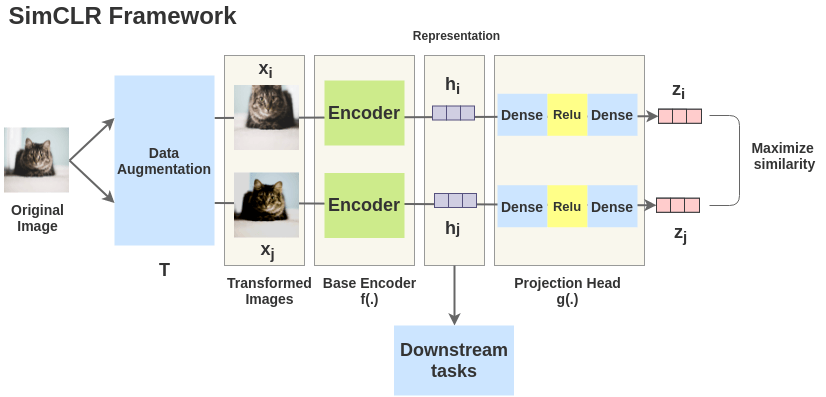
Source: https://amitness.com/2020/03/illustrated-simclr/
Essentially, SimCLR applies data augmentation on a single image to obtain 2 augmented images, and then optimises by maximising the similarity between the representations of both augmented images.
How is similarity computed?¶
SimCLR applies cosine similarity between the embeddings of images, \(z_i, z_j\):
where \tau is the temperature that scales the range of cosine similarity.
What loss does SimCLR optimise?¶
SimCLR uses NT-Xent loss (Normalized Temperature-scaled Cross-entropy loss).
First, obtain the Noise Contrastive Estimation (NCE) loss:
Then compute average loss over all pairs in the batch of size N=2:
So what?¶
The encoder representations of the image (not the projection head representations) can be used for downstream tasks such as ImageNet classification.
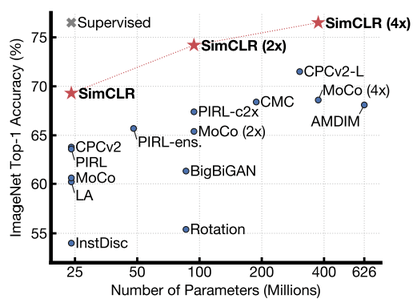
Source: https://arxiv.org/abs/2002.05709
It is shown that on ImageNet ILSVRC-2012, it achieves 76.5% top-1 accuracy, a 7% improvement over the previous SOTA self-supervised method, Contrastive Predictive Coding, and comparable with supervised method ResNet50.