SwAV¶

Content¶
Why SwAV?
SwAV Loss
SwAV Computing Codes Online
Sinkhorn-Knopp Algorithm
Why SwAV Works
Why SwAV?¶
About¶
SwAV (Swapping Assignments between multiple Views of the same image) is introduced in Unsupervised Learning of Visual Features by Contrasting Cluster Assignments ([CMM+20]).
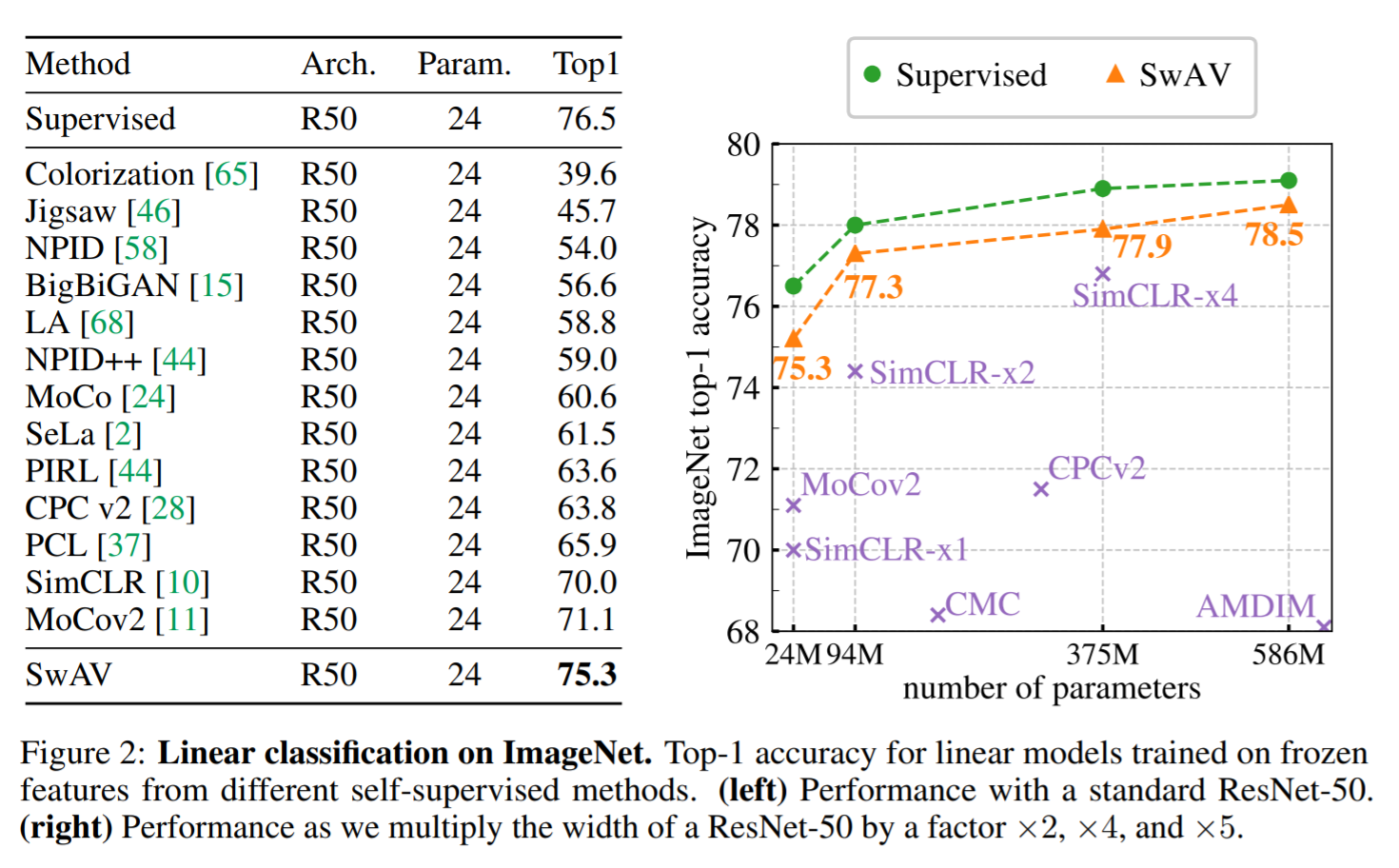
SwAV achieves 75.3% top-1 accuracy on ImageNet with ResNet-50 for linear models trained on frozen features, which is only 1.2% difference from the supervised method (76.5%), closing the gap between unsupervised and supervised learning representation of visual features.
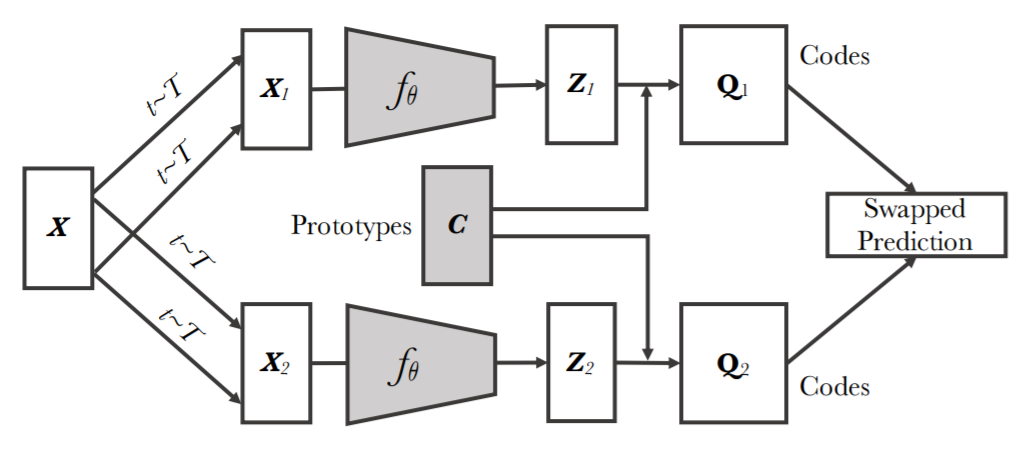
SwAV is an unsupervised contrastive learning method that simultaneously clusters the data while enforcing consistency between cluster assignments produced for different augmentations (or “views”) of the same image, and uses a “swapped” prediction mechanism by predicting the code of a view from the representation of another view.
SwAV can be trained with large and small batches and can scale to unlimited amounts of data. SwAV also does not require a large memory bank or a special momentum network, therefore is more memory efficient than previous contrastive methods.
SwAV also introduces a new augmentation “multi-crop” that increases the number of views with no computational or memory overhead.
Motive¶
Recent contrastive learning methods for unsupervised visual representation learning uses:
A contrastive loss that compares pairs of images to push away semantically different images while pulling together semantically similar images
Image augmentations that define invariances encoded in the features.
Instance discrimination (contrasting instances of image views) is not practical for all pairwise comparisons on a large dataset. Clustering-based methods thus approximate task by discriminating between clusters images with similar features instead of individual images.
However, current clustering-based methods are computationally inefficient.
Therefore, SwAV proposes a scalable, online clustering-based method, and a “swapped” prediction problem to learn visual features.
Reference: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (Caron et al. NeurIPS 2021)
SwAV Loss¶
SwAV can be interpreted as contrasting between multiple images views by comparing cluster assignments instead of their features. SwAV does this by computing a code from one view and predicting that code from the other view.
Given image x, augment and obtain the 2 views’ image features zt,zs.
Match image features zt,zs to prototypes {c1,...,ck} to compute codes qt,qs.
Set up the “swapped” prediction problem with the loss function: L(zt,zs)=l(zt,qs)+l(zs,qt) where l(z,q)=∑kq(k)slogp(k)t measures fit between features z and code q, where p(k)t=exp(1τz⊺tck)∑k′exp(1τz⊺tck′).
Taking this loss over all images and pairs of data augmentations lead to: −1N∑Nn=1∑s,t∼T[1τz⊺ntCqns+1τz⊺nsCqnt−log∑Kk=1exp(z⊺ntτ)−log∑Kk=1exp(z⊺nsτ)]
This loss is minimized with respect to prototypes C and parameters θ of image encoder fθ.
SwAV Computing Codes Online¶
SwAV clusters instances to the prototypes C, and compute codes using prototypes C such that all instances are equally partitioned by the prototypes.
Given image features Z=[z1,...,zB], map them to prototypes C=[c1,...,ck], where the mapping (codes) is denoted by Q=[q1,...,qB].
Q is optimized to maximized similarity between features and prototypes using maxQ∈QTr(Q⊺C⊺Z)+εH(Q) where H(Q)=−∑i,jQijlogQij is the entropy function.
C⊺Z=[c1c2][z1z2z3]=[c1z1c1z2c1z3c2z1c2z2c2z3]
Tr([q11q21q12q22q13q23][C⊺Z])=q11c1z1+q21c2z1+q12c1z2+q22c2z2+q13c1z3+q23c2z3
Q is a range of continuous values between 0 and 1. Q is 0 for the general case and close to 1 when a z representation is close to its prototype vector C. This is because optimizing Q to maximise the trace Tr(Q⊺C⊺Z) results in the dot products where c and z are close together will take a bigger value. The values of q will try to be maximised.
However, the maximization of values of q are regularized by H(Q)=−∑i,jQijlogQij. The closer qij is to 0, the bigger the logQij value will be, and the maximum of QijlogQij will be in the middle of 0 and 1. A higher entropy will give a more homogenous distribution of Q.
Q is optimized using the Sinkhorn-Knopp algorithm.
Reference: SwAV Loss Deep Dive by Ananya Harsh Jha
Sinkhorn-Knopp Algorithm¶
The goal of optimal transport is to transform one probability distribution into another with minimal cost.
For example, let us allocate desserts to people according to preferences while constraining portion sizes.
Let r=(3,3,3,4,2,2,2,1), the portion size of dessert each person can eat (n-dimensional).
Let c=(4,2,6,4,4), the amount of each dessert available (m-dimensional).
Let U(r,c)={P∈Rn×m>0|P1m=r,P⊺1n=c} be the set of positive n×m matrices for which rows sum to r and columns sum to c, which is the set of ways of allocating desserts to the people.
Let M be the (n×m) cost (negative preference) matrix.
The optimal transport problem is formally posed as dM(r,c)=minP∈U(r,c)∑i,jPijMij the optimal transport between r and c.
The Sinkhorn distance is dM(r,c)=minP∈U(r,c)∑i,jPijMij−1λh(P) where h(P)=−∑i,jPij is the information entropy of P that acts as regularization.
The Sinkhorn-Knopp algorithm is an efficient method to obtain the optimal distribution matrix P∗λ and the associated dλM(r,c) based on the fact that elements of the optimal matrix are of the form (P∗λ)ij=αiβje−λMij with α1,...,αn and β1,...,βn are constants to ensure rows and columns sum to r and c respectively.
The Sinkhorn-Knopp algorithm is basically
Initialise Pλ=e−λM.
Repeat 3-4 until convergence:
Scale the rows such that row sums match r.
Scale the columns such that column sums match c.
Reference: Notes on Optimal Transport by Michiel Stock
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
r = np.array([3,3,3,4,2,2,2,1]) # amount each of the 7 people can eat
c = np.array([4,2,6,4,4]) # portions of the 5 desserts available
M = np.array([[2,2,1,0,0],
[0,-2,-2,-2,2],
[1,2,2,2,-1],
[2,1,0,1,-1],
[0.5,2,2,1,0],
[0,1,1,1,-1],
[-2,2,2,1,1],
[2,1,2,1,-1]]) # (n x m) preferences matrix
M = -M # converting preferences to cost

"""
Sinkhorn-Knopp Algorithm
"""
def sinkhorn_knopp(M, r, c, lam):
n, m = M.shape
P = np.exp(- lam * M)
P /= P.sum()
u = np.zeros(n)
while np.max(np.abs(u - P.sum(1))) > 1e-8:
u = P.sum(1)
P *= (r / u).reshape((-1,1))
P *= (c / P.sum(0)).reshape((1,-1))
return P
P = sinkhorn_knopp(M, r, c, lam=10)
pd.DataFrame(P).plot.bar(stacked=True)
plt.show()
Why SwAV Works¶
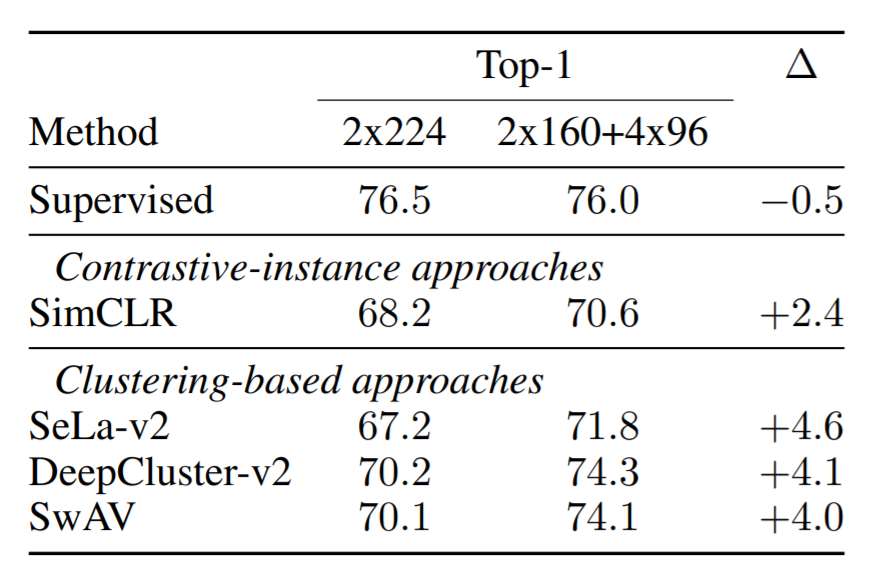
SwAV authors re-implemented and improveed previous clustering-based models to compare with SwAV.
DeepCluster-v2 obtains 75.2% top-1 accuracy on ImageNet versus 75.3% for SwAV.
However, DeepCluster-v2 is not online, making it impractical for extremely large datasets, e.g. billion scale trainings which sometimes use only a single training epoch.
As seen, SwAV can work online and therefore can scale better to unlimited amounts of data.
- CMM+20
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. arXiv preprint arXiv:2006.09882, 2020.